It takes data to do a data cleanse right
For any data automation project, whether you’re looking to do a data cleanse, normalization, enrichment, or segmentation, you need 3 key data cleaning tools: rules, connectors, and reference data.
1. Rules
Rules are the robots. Rules perform the repetitive task of searching for data then perform the prescribed data transformation. Openprise Data Rules does exactly that. There’s much to discuss about the nuances of rules, you can learn more here.
2. Connectors
For continuous automation, you need connectors to extract data from sources systems, like Salesforce. The connectors also push processed data back into the source systems, or to other systems like reporting tools. Openprise offers a growing list of connectors as well.
3. Reference Data
The data cleansing tool that is often overlooked is reference data. Reference data is the content for the rules to automate. If you break down the most common data automation use cases down to the lowest task level, they involve 3 common steps:
- Search: Search for the data that needs to be processed
- Lookup: Look up the data used for transformation
- Write: Replace existing data or add new data using information from the lookup
Step 1 is a straight forward search. Fuzzy search is critical in making this process scalable and manageable. We will touch on this at the end. You can read more about Openprise’s fuzzy search technology in this blog post.
Step 2 is where reference data comes into play. Reference data contains combinations of lists and mappings of the following nature:
- List of values and their common aliases, e.g. state and country names
- List of values with additional information, e.g. ZIP code with city and state information
- Cross-mappings between lists, e.g. SIC to NAISC mappings
As an example, here’s the States, Provinces, and Regions reference data set from Openprise:

Two different approaches
So why is reference data important? Because it’s key when it comes to making data automation practical and manageable. There are two approaches to automating data rules. The first one relies on rules only; the second one uses rules + reference data.
The rules-only approach
The first approach simply lets users configure the rules to search for specific data and perform the transformation. This is how most CRM and marketing automation solutions approach data cleansing and normalization. It’s a straight forward extension of their transactional rules engine. This approach sounds reasonable in theory, but is completely impractical. Let’s illustrate this with a common example of normalizing state and country names in address data.
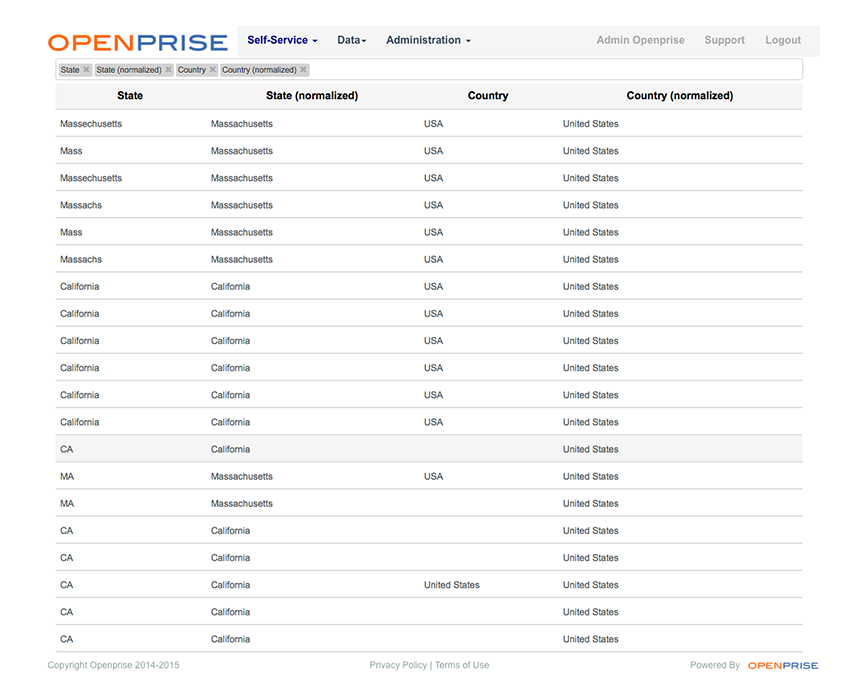
Anybody who works with address data knows how dirty it can be. Typos, missing data, and abbreviations can render your data completely unusable. Here is a screenshot of an actual Marketo leads database showing the “before” original state and country fields and the “after” state and country fields. This data was normalized using Openprise data rules.

To do these 2 tasks using the rules-only approach, you need to configure the following to cover just these 6 countries: US, Canada, UK, Germany, France, and Australia:
- 238 rules to normalize country names
- 125 rules to normalize state and province names
- 6 rules to infer country names
Within each rule, you have to specify
- Every known alias, abbreviation, and common typos
- Language and regional variations
The amount of work involved in initial setup and maintenance makes this approach impractical. The results are usually not good unless you managed to be exhaustively perfect in your rule configuration. This is why marketing and sales ops do not perform data clean up and normalization inside their CRM and marketing automation tools.
The rules + reference data approach
The better approach is to combine rules with reference data to reduce the complexity and scale of configuration and management. Using reference data sets like the one shown above, Openprise data rules perform the following tasks:
To normalize the state, province, and country names:
- Step 1: Search for state and country names and all their common aliases, including abbreviations and codes.
- Step 2: Look up the normalized state and country names in the reference data set using the name-to-alias mapping.
- Step 3: Write the normalized state and country names
To infer a missing country name from a known state or province name:
- Step 1: Search for known state and province names using the state reference data set.
- Step 2: Look up the country name associated with the state or province.
- Step 3: Fill in the missing country name
In comparison to the rules-only approach, the amount of configuration required in setting up Openprise rules using reference data is:
- 1 rule to normalize state names and infer missing country name
- 1 rule to normalize country names
In addition, the Openprise results are much better because of better language coverage, more comprehensive alias list, and fuzzy search.
That leads to the question, where do you get the reference data? If you are doing these tasks by writing your own SQL jobs, then you will have to build these reference data set by looking through open data repositories, developer forums, and Wikipedia. Openprise offers a growing number of reference data sets to our customers, accessible as open data in the catalog. You can see the full list here. You can start with our standard data set to get going quickly, then customize the data set to your business as needed.
A word on fuzzy search
As promised, a word on fuzzy search. To make the reference data approach work well, you also need fuzzy search in your rules engine. In the above state normalization example, see all the different variations of Massachusetts that were found in the search results? This was done with only 3 aliases in the reference data: Massachusetts, MA, and Mass. Without fuzzy search, you will have to have a much more extensive list of aliases that cover common typos and regional variations, which is neither practical nor scalable.
Give this a try. We can perform data scrubbing in less than 30 minutes, including data import and rule setup.
Leave a comment